Internet Archive Wayback Machineは、世界中のWEBサイトのコンテンツを自動的に保存している無料のサービスです。
サイトを誤って削除しまった場合にWayback Machineで探すことでデータを見つけることができます。またオールドドメインなど取得する際にWayback Machineで過去の運用サイトを調べることもできますし、いつから開設されたサイトなのかも調べたりすることもできたりします。
ここではInternet Archive Wayback Machineの使い方について解説します。
目次
Internet Archive Wayback Machineの使い方
Internet Archive Wayback Machineの使い方を目的別に解説します。
サイトの過去コンテンツを調べる
Internet Archive Wayback Machineにアクセスします。

調査したいURLを入力して「BROWSE HISTORY」をクリックします。今回入力したURLは、過去に運用されていたドメインになります。
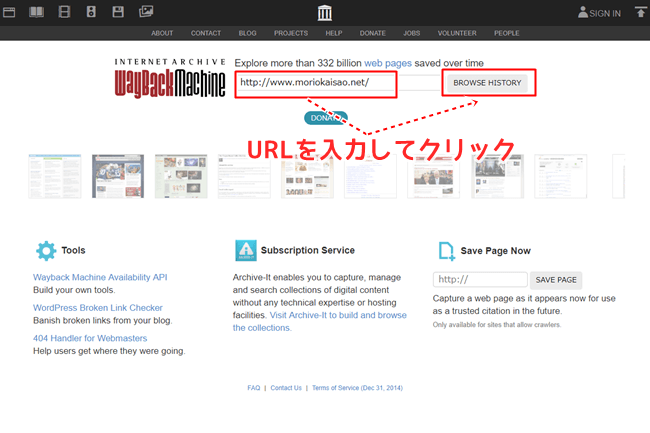
ドメインの運用歴がわかるカレンダーが表示されます。
「Saved 30 times between June 11, 2009 and January 10, 2016.」と表示されている部分が、このサイトのデータを取得した日が2009年6月11日で、最終取得が2016年1月10日ということがわかります。
つまり、2009年6月から運用開始され2016年1月ごろまで利用されたドメインということになります。
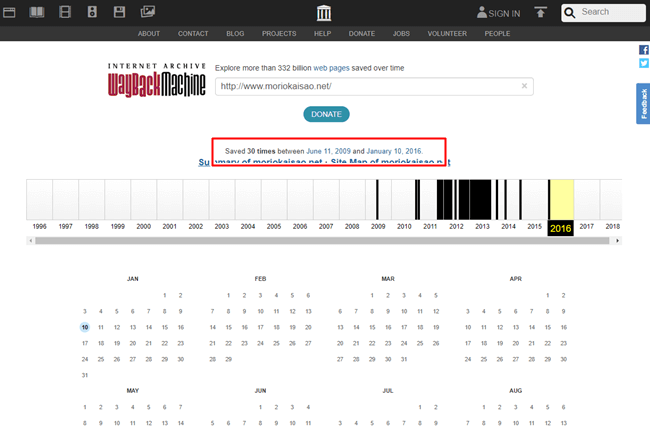
つぎにどういったサイトコンテンツだったかを調べてみましょう。
黒く塗られている縦線ををクリックします。この縦線部分は、Internet Archive Wayback Machineがデータ取得した回数で長くなったり短くなったりを表しています。
今回は「2013年」をクリックしてみます。
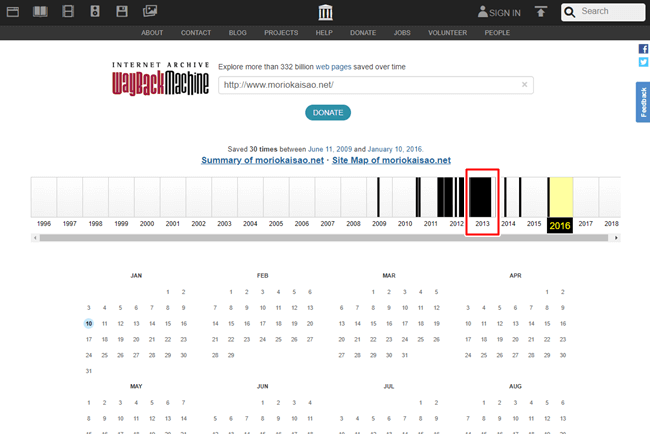
画面下部に2013年のカレンダーが表示されます。カレンダーの中に青い丸で表示されている部分は、コンテンツを取得した日でクリックできるようになっています。
青い丸で表示されている部分をクリックします。
コンテンツを取得した当時のWEBページを閲覧することができます。
今回調査したドメインは、とある議員さんが利用したドメインということがわかります。
※モザイク部分は一般人になった可能性もあるためモザイク加工を入れています。
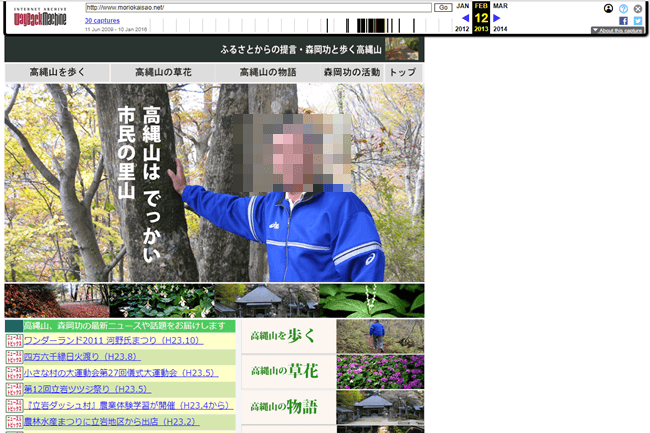
内部リンクなども自動的に保存されたデータにリンクが変換されていて、閲覧することもできるようになっています。
現在のサイトコンテンツを保存したい場合
Internet Archive Wayback Machineは世界のWEBサイトを定期的にクローリングしてコンテンツを保存しています。
自サイトがどのタイミングで保存されるかは、Internet Archive Wayback Machineのクローラーが回ってこないと保存されないため、いつ保存されるかわかりません。
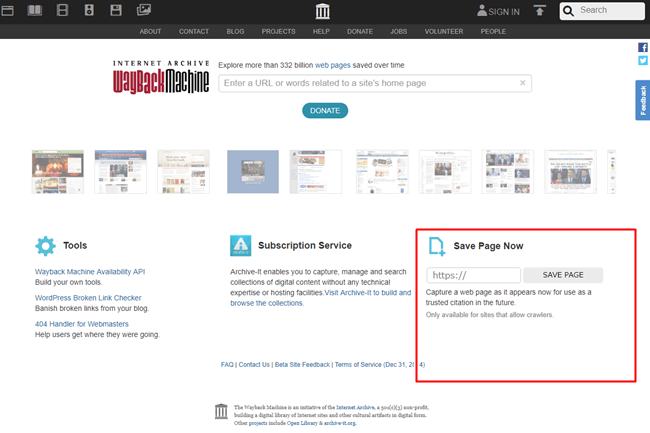
ですが、保存したいタイミングで保存できるように手動でコンテンツを保存することもできる機能が用意されています。
サイトのコンテンツを保存するには、Internet Archive Wayback Machineのトップページにある「Save Page Now」欄から現状のコンテンツを保存することができます。
保存されたデータを削除する
誤って公開してはいけないコンテンツなどが保存されている場合、保存されたデータを削除することもできます。
公式サイトのよくある質問部分に削除方法が記載されます。
How can I have my site’s pages excluded from the Wayback Machine?
You can send an email request for us to review to info@archive.org with the URL (web address) in the text of your message.
英文を翻訳すると・・・
Wayback Machineからサイトのページを除外するにはどうすればよいですか?
メッセージのテキストにURL(ウェブアドレス)を記入してinfo@archive.orgにお送りください。
最後に
Internet Archive Wayback Machineの使い方について解説しました。このサービスは無料で利用でき、過去のWEBコンテンツを閲覧することができます。